Discrete Inverse Problems and Regularization
Contents
2. Discrete Inverse Problems and Regularization¶
In this lecture we consider inverse problems that can be posed as a system of linear equations
with \(K \in \mathbb{R}^{m\times n}\) a given matrix and \(f\in \mathbb{R}^{m}\) the data. The goal is to find a solution \(u \in \mathbb{R}^n\) that (approximately) satisfies the equations.
2.1. Well-posedness¶
The first questions we address in detail are those of existence, uniqueness and stability of the solution. We discern the following cases:
If \(m = n\) and \(K\) has full rank, it is invertible and the solution is given by
If \(m > n\) and \(K\) has rank \(n\), the system of equations may be inconsistent in which case a solution does not exist when \(f\) is not in the range of \(K\).
If \(m < n\) and \(K\) has rank \(m\), we can always find a solution but it may not be unique because \(K\) has a non-trivial null-space.
If \(K\) does not have maximal rank, the system of equations may be both inconsistent and \(K\) can have a null-space.
Stability in this context means that errors in the data do not get amplified too much. For now, we’ll only consider stability in case the solution exists and is unique. Consider the systems \(K\widetilde{u} = f\) and \(K\widetilde{u}^{\delta} = f^{\delta}\) for which we have
where \(\|u\|\) denotes any vector norm on \(\mathbb{R}^n\) and \(\|K\|\) denotes its corresponding (induced) matrix norm.
Since \(\|f\| = \|K\widetilde u\| \leq \|K\| \|\widetilde u\|\), we can express the relative error as
The quantity \(\kappa(K) = \|K\|\|K^{-1}\|\) is called the condition number of \(K\).
2.2. Pseudo inverse¶
Next, we discuss how we may define solutions to inconsistent or underdetermined systems of equations. For this, we’ll use the singular value decomposition of the matrix \(K\).
If \(m > n\), the system is inconsistent when \(f\) is not in the range of \(K\). If \(K\) has full rank we can express it as
with \(U_n = (u_1, u_2, \ldots, u_n), V_n = (v_1, v_2, \ldots, v_n)\) containing the first \(n\) left and right singular vectors and \(\Sigma_n\) is a diagonal matrix containing the singular values \(\sigma_1 \geq \sigma_2 \geq \ldots \geq \sigma_{n} > 0\). We can then attempt to solve a modified system of equations
where \(U_nU_n^* f\) projects \(f\) onto the range of \(K\). We find
where \(K^\dagger\) denotes the Moore-Penrose pseudo inverse of \(K\).
This coincides with the least-squares solution
Indeed, by setting the gradient to zero, we find the normal equations
so
Example: An overdetermined system of equations
Consider solving
The system of equations is obviously not consistent. The corresponding normal equations:
do have a unique solution, \(u = (4/11,4/11)^T\).
If, on the other hand \(m < n\) and \(K\) has full rank, a solution exists but is not unique. In this case, we can look for the smallest solution (i.e., one that does not have any contributions in the null-space of \(K\)). This means we look for a solution that is spanned by the first \(m\) right singular vectors, denoted by \(V_m = (v_1, v_2, \ldots v_m)\):
with \(\widetilde u = V_m z\). We find that this solution is given by
where \(U_m = (u_1, u_2, \ldots u_m)\), and \(\Sigma_m\) contains the non-zero singular values \(\sigma_1 \geq \sigma_2, \ldots, \sigma_m > 0\). Showing that this indeed yields the solution with the smallest norm is the subject of one of the assignments. The corresponding variational problem is
Example: An underdetermined system of equations
Consider solving
The corresponding normal equations are given by \(2v = 1\), and gives the solution \(u = v (1,1)^T\). In effect this means that we have added an equation to the system: \(u_1 - u_2 = 0\).
If the matrix does not have full rank we may still employ the pseudo-inverse, which for a matrix of rank \(k \leq \min\{m,n\}\) is defined as follows.
Definition: Moore-Penrose pseudo inverse
The pseudo-inverse of a matrix \(K \in \mathbb{R}^{m,n}\) with rank \(k \leq \min\{m,n\}\) is defined in terms of the singular value decomposition as
where \(V_k = (v_1, v_2, \ldots, v_k)\), \(U_k = (u_1, u_2, \ldots, u_k)\) and \(\Sigma_k\) contains the \(k\) largest singular values.
Note that the pseudo inverse allows us to define a unique solution, it is not necessarily stable as \(\|K\|_2\|K^{\dagger}\|_2 = \sigma_1/\sigma_k\) may still be large. To study this issue in more detail, express the solution as
We note the component in \(f\) corresponding to \(v_i\) is amplified by \(\sigma_i^{-1}\). Thus if \(f\) has (noise) components that correlate with \(v_i\)’s corresponding to very small singular values, these noise components get amplified. Generally, we do not expect problems if \(|\langle u_i, f\rangle|\) decays faster with \(i\) than the singular values \(\sigma_i\). This is called the discrete Picard condition [Hansen, 1990].
Definition: Discrete Picard Condition
The vector \(f \in \mathbb{R}^m\) satisfies the discrete Picard condition for the problem \(Ku=f\) if the coefficients \(|\langle u_i, f\rangle|\) decay faster than the singular values \(\sigma_i\) of \(K\), where \(u_i\) denotes the left singular vectors of \(K\).
import numpy as np
import matplotlib.pyplot as plt
import matplotlib as mpl
mpl.rcParams['figure.dpi'] = 300
from myst_nb import glue
# define forward operator
def getK(n):
x = np.linspace(0,1,n)
K = np.diag(np.exp(-5*x))
return K,x
# parameters
n = 100
sigma = 1e-2
K,x = getK(n)
# define ground truth and compute data
u = np.exp(-10*x)
f = K@u
# add noise
noise = np.random.randn(n)
f_delta = f + sigma*noise
# SVD
U, s, Vh = np.linalg.svd(K, full_matrices=True)
# apply pseudo inverse
uhat = Vh.T@np.diag(1/s)@U.T@f_delta
# plot
fig, ax = plt.subplots(1,1)
ax.semilogy(s,'*',label=r'$\sigma_i$')
ax.semilogy(np.abs(U.T@f),'o',label=r'$|\langle u_i, f\rangle|$')
ax.semilogy(np.abs(U.T@f_delta),'o',label=r'$|\langle u_i, f^{\delta}\rangle|$')
ax.semilogy(np.abs(U.T@f) + np.sqrt(2/np.pi)*sigma,'k--')
ax.set_xlabel(r'$i$')
ax.set_ylim([1e-6,2])
ax.set_xlim([0,n])
ax.legend()
glue("picard", fig, display=False)
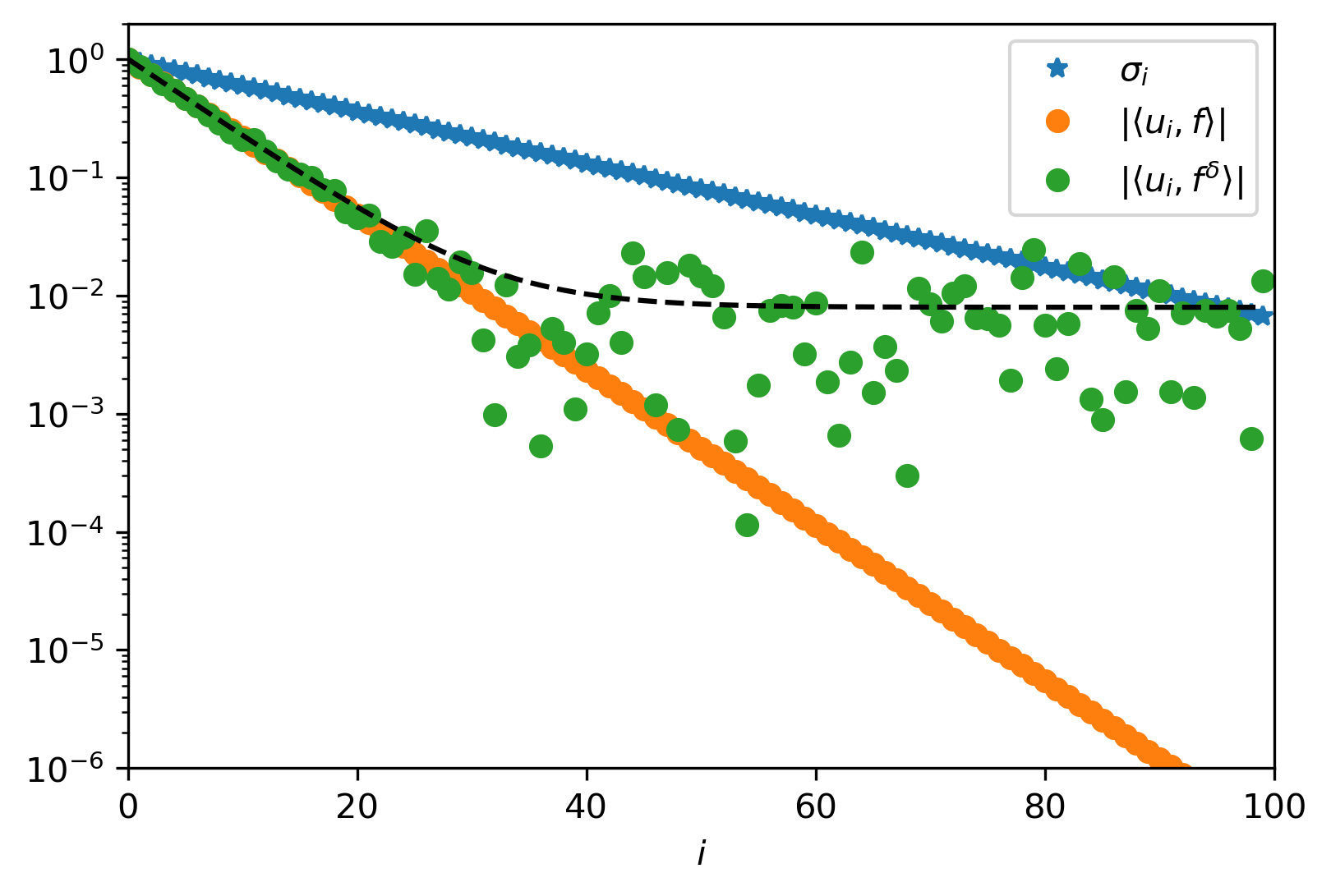
Example An ill-posed problem
As forward operator we take a diagonal matrix with entries
We generate noisy data \(f^\delta = K \overline{u} + e\) with \(\overline{u}_i = \exp(-10 \cdot i/(n-1))\) and \(e_i\) normally distributed with mean zero and variance \(\sigma^2\). We then find that
and
Since \(e_i\) is normally distributed, its absolute value follows a folded normal distribution. This allows us to compute the expected upper bound
We conclude that \(|\langle u_i, f^\delta\rangle|\) does not decay exponentially as the singular values do and hence do not satisfy the discrete Picard condition.
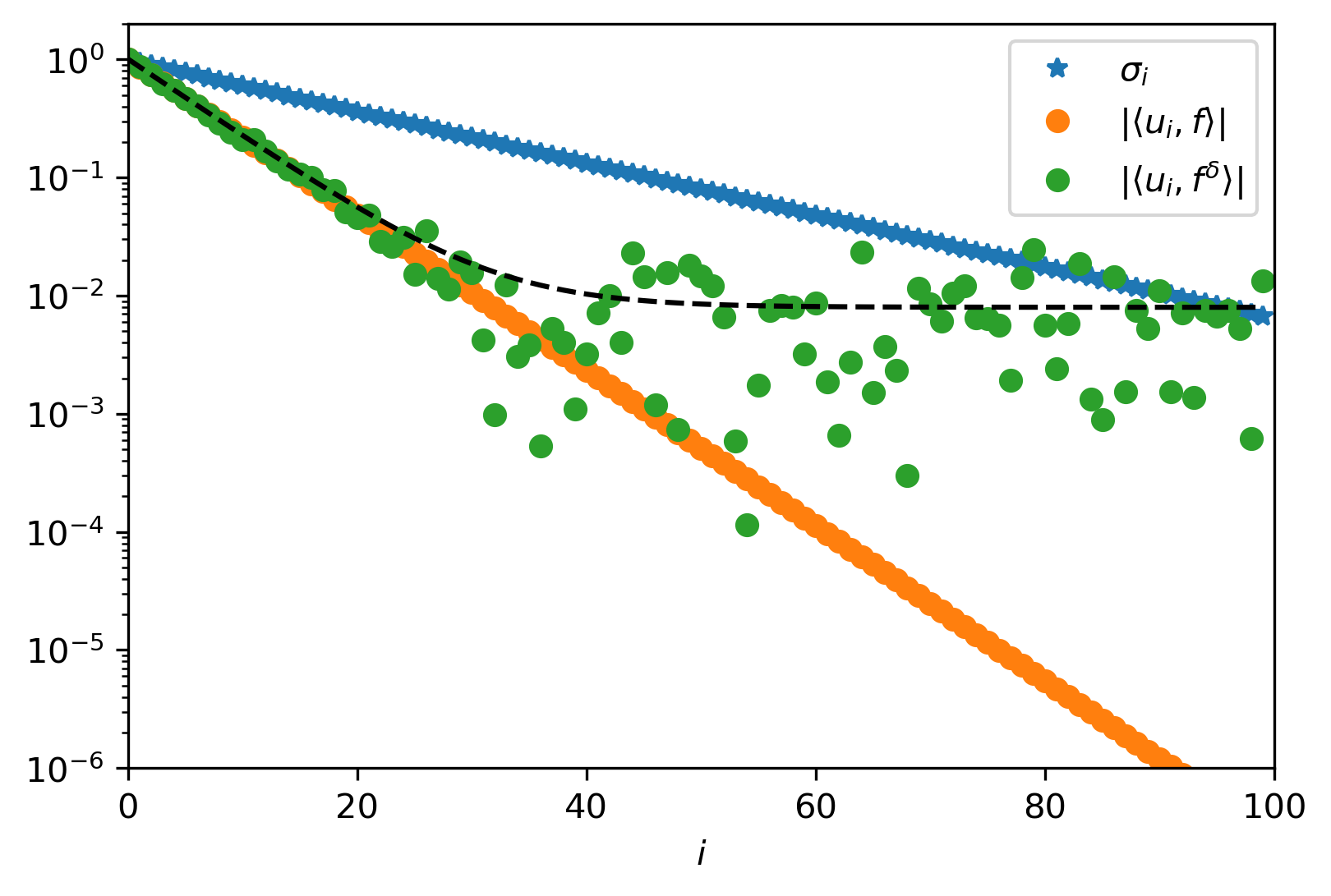
Fig. 2.1 An example of the singular values and the coefficients \(|\langle u_i, f\rangle|\) and \(|\langle u_i, f^\delta\rangle|\) for \(n = 100\) and \(\sigma = 10^{-2}\). We see that \(f\) does satisfy the discrete Picard condition while \(f^\delta\) does not.¶
2.3. Regularisation¶
To stabilize the problem we can modify the pseudo inverse in several ways to avoid dividing by small singular values. One option is to simply ignore small singular values and choose a cut-off value and define the solution as
where \(r_{\alpha}\) is applied component-wise to the diagonal of the matrix \(\Sigma_k\) as
This gives rise to the Truncated Singular Value Decomposition (TSVD).
Definition: Truncated Singular Value Decomposition (TSVD)
The TSVD-regularized solution to the equation \(Ku = f\) is given by
where \(\{(u_i,v_i,\sigma_i)\}_{i=1}^k\) denotes the singular system of \(K\) and \(k_{\alpha} \leq k\) is chosen so that \(\sigma_i \geq \alpha\) for \(i \leq k_{\alpha}\).
Another option to avoid dividing by small singular values is to add small positive constant to shift the singular values away from zero. This gives rise to Tikhonov regularization.
Definition: Tikhonov regularisation
The Tikhonov-regularised solution to the equation \(Ku = f\) is given by
where \(\{(u_i,v_i,\sigma_i)\}_{i=1}^k\) is the singular system of \(K\). This corresponds to setting \(r_{\alpha}(s) = s/(s^2 + \alpha)\) in (2.1).
Unlike the TSVD, Tikhonov regularisation has a corresponding variational problem:
whose well-posedness can be easily established by writing down the corresponding normal equations
Indeed, it is easily verified that \(K^* K + \alpha I\) has full rank whenever \(\alpha > 0\).
Of course, one may think of other types of regularization by defining an appropriate function \(r_{\alpha}\). Intuitively, we would like
\(r_{\alpha}(s) = s^{-1}\) as \(\alpha \rightarrow 0\)
\(r_{\alpha}(0) < \infty\) for any \(\alpha > 0\)
\(r_{\alpha}(s) \rightarrow 0\) as \(\alpha \rightarrow \infty\)
One example is Lavrentiev regularization, with:
Conditions on regularization schemes and methods for choosing \(\alpha\) will be discussed in more detail in the chapter on Inverse Problems in Function Spaces.
In general, we can think of regularization for linear problems as defining a modified pseudo-inverse of \(K\):
Stability of regularized solutions defined by (2.1) then follows by considering the largest singular value of \(K_{\alpha}^\dagger\), which can be made arbitrarily small by increasing \(\alpha\). On the other hand, increasing \(\alpha\) will also introduce a bias in the solution. This trade-off is called the bias-variance trade-off:
Definition: Bias-variance trade-off
Here, we compare the regularised solution from noisy data \(\widetilde{u}_{\alpha, \delta} = K_{\alpha}^\dagger f^{\delta}\) and the ideal solution \(\widetilde{u} = K^{\dagger}f\):
If \(\alpha \downarrow 0\), the bias goes to zero, but possibly leads to a large variance. Large \(\alpha\) on the other hand reduces the variance but leads to a large bias. Ideally, the regularisation parameter is chosen in such a way that the small singular values are stabilised and the large ones are hardly effected.
We can make a similar decomposition of the error between the ground truth \(\overline{u}\) and the regularised solution
import numpy as np
import matplotlib.pyplot as plt
from myst_nb import glue
# define forward operator
def getK(n):
x = np.linspace(0,1,n)
K = np.diag(np.exp(-5*x))
return K,x
# parameters
n = 100
sigma = 1e-2
K,x = getK(n)
# define ground truth and compute data
u = np.exp(-10*x)
f = K@u
# add noise
noise = np.random.randn(n)
f_delta = f + sigma*noise
# SVD
U, s, Vh = np.linalg.svd(K, full_matrices=True)
# error, bias and variance for TSVD
error = np.zeros(n)
bias = np.zeros(n)
variance = np.zeros(n)
for k in range(1,n):
uk = Vh[:k,:].T@np.diag(1/s[:k])@U[:,:k].T@f
uk_delta = Vh[:k,:].T@np.diag(1/s[:k])@U[:,:k].T@f_delta
error[k] = np.linalg.norm(u - uk_delta)
bias[k] = np.linalg.norm(u - uk)
variance[k] = np.linalg.norm(uk - uk_delta)
# plot
k = np.linspace(0,n-1,n)
fig, ax = plt.subplots(1,1)
ax.plot(k,bias,label='bias')
ax.plot(k,variance,label='variance')
ax.plot(k,np.exp(5*k/(n-1))*sigma*np.sqrt(k+1) + np.exp(-10*(k+1)/(n-1))*np.sqrt(n-k-1),'k--')
ax.set_xlabel(r'$k$')
ax.set_ylabel(r'error')
ax.set_xlim([1,n])
ax.set_ylim([0,5])
ax.legend()
glue("bias_variance",fig,display=False)
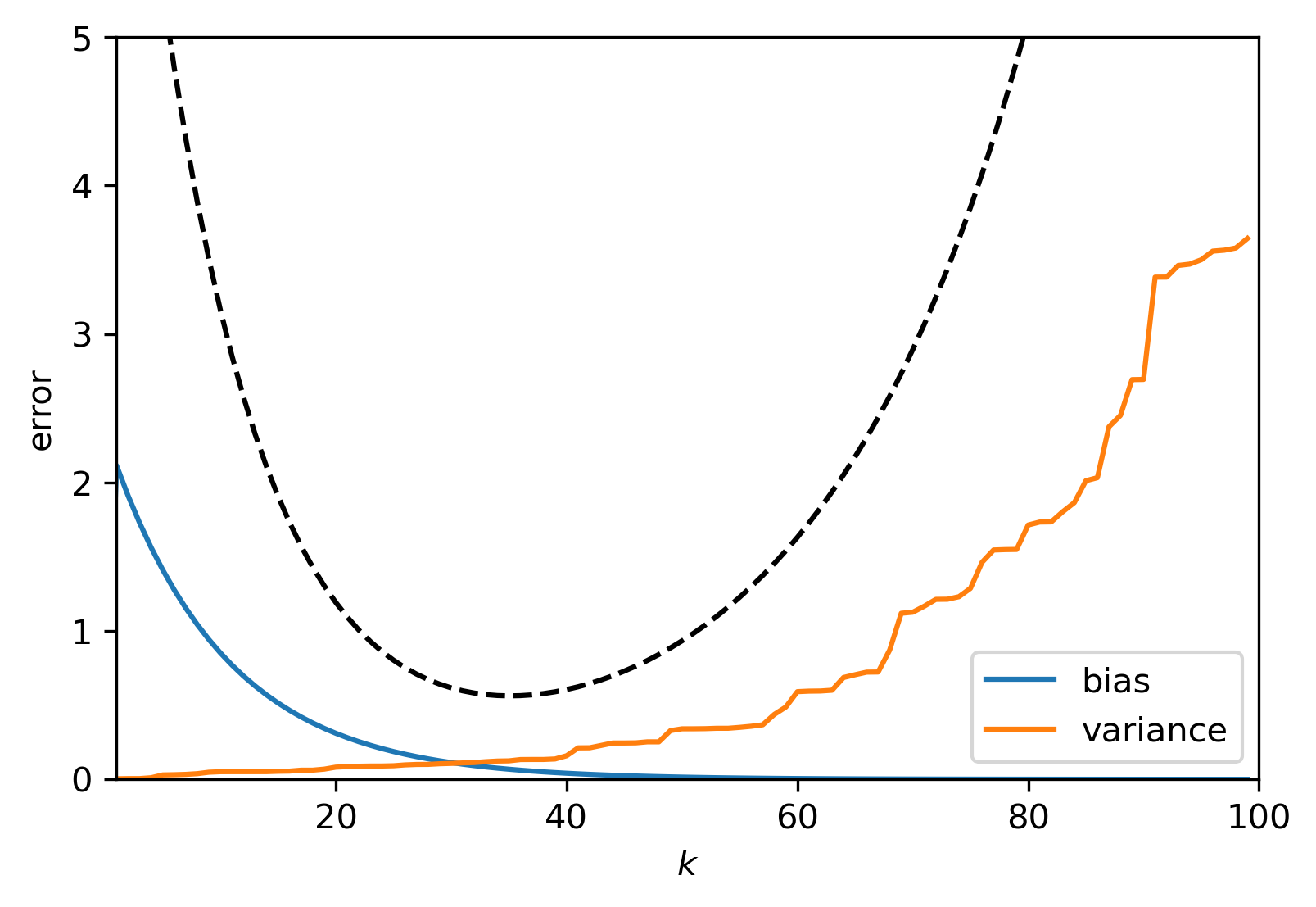
Example An ill-posed problem, cont’d
Using the same forward operator and ground truth as the previous example and use TSVD-regularisation to regularise the problem. Using the truncation rank, \(k\), as the regularisation parameter we find that
Thus, the error becomes
in which we recognise the bias and variance terms. In expectation, the upper bound for the error is then given by \((k+1)e^{10k/(n-1)}\sigma + (n-k-1)e^{-10(k+1)/(n-1)}\). While not very tight, it does suggest that there is an optimal \(k\).
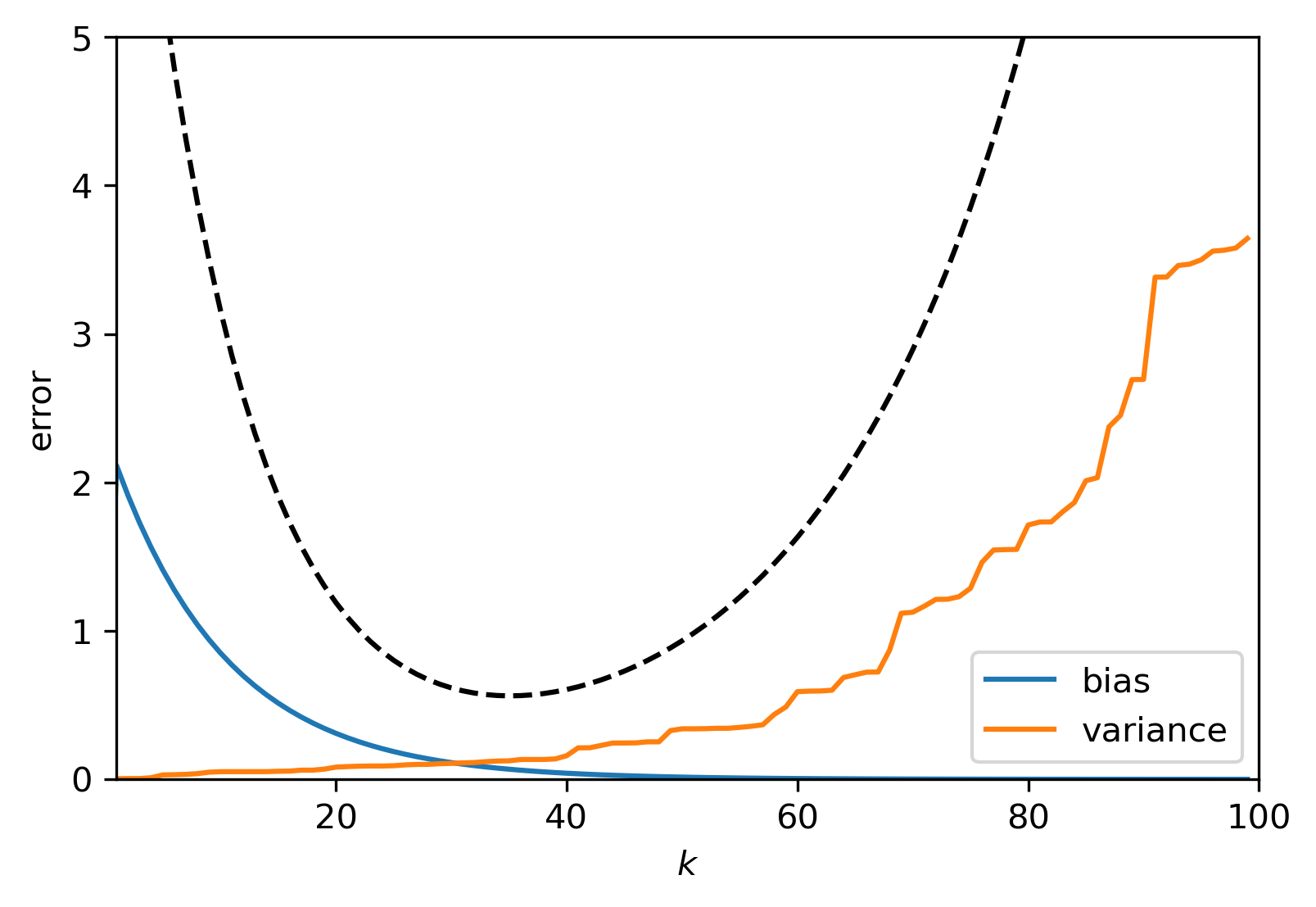
Fig. 2.2 An example of the error \(\|\overline{u} - K_{\alpha}^\dagger f^\delta\|_2\) and corresponding bias and variance for \(n = 100\) and \(\sigma = 10^{-2}\). As predicted, the bias decreases with \(k\) while the variance increases. The optimal \(k\) for this noise level lies at \(k \approx 30\). Look at Fig. 2.1, do you see why this is the optimal \(k\)?¶
2.4. Exercises¶
2.4.1. Pseudo-inverse¶
Show that for a given matrix \(K \in \mathbb{R}^{m\times n}\):
\(KK^\dagger\) is an orthogonal projection on to the range of \(K\)
\(I - K^\dagger K\) is an orthogonal projection to to the null-space of \(K\)
Answer
Express the pseudo-inverse in terms of the SVD as \(K^\dagger = V_k\Sigma_k^{-1}U_k^*\) and find \(KK^\dagger = U_kU_k^*\). Because \(U_k = (u_1, u_2, \ldots, u_k)\) is an orthonormal basis for the range of \(K\) we find that \(KK^\dagger\) is an orthogonal project on to the range of \(K\).
Following a similar argument we find that \(K^\dagger K = V_kV_k^*\) where \(V_k = (v_1, v_2, \ldots, v_k)\) spans the orthogonal complement of the null-space of \(K\) (recall that the null-space of \(K\) is spanned by \((v_{k+1}, \ldots, v_{\min_{m,n}})\)).
2.4.2. Least-squares and minimum-norm solutions:¶
Given a system of equations \(Ku = f\) with \(K\in\mathbb{R}^{m\times n}\):
For \(m > n\) and rank(\(K\)) = \(n\), show that the pseudo-inverse gives the solution \(u = K^\dagger f\) with the smallest residual \(\|Ku - f\|_2\)
For \(m < n\) and rank(\(K\)) = \(m\), show that the pseudo-inverse gives the solution \(u = K^\dagger f\) with the smallest norm \(\|u\|_2\)
For \(m > n\) and rank(\(K\)) = \(r < n\), show that the pseudo-inverse gives the solution that minimizes both \(\|Ku - f\|_2\) and \(\|u\|_2\).
Answer
We can construct the solution with the smallest residual by formulating the corresponding normal equations \(K^*Ku = K^*f\). Since rank(\(K\)) = \(n\), these have a unique solution. Expressing \(K\) and \(K^\dagger\) in terms of the SVD of \(K\) we find that \(K^\dagger = (K^*K)^{-1}K^*\) and hence that pseudo-inverse yields the solution to the normal equations.
Here, the system solutions of the form \(v = u + z\) with \(u = K^\dagger f\) and \(Kz = 0\). We find that \(\|v\|_2^2 = \|u\|_2^2 + 2 \langle z, K^{\dagger} f \rangle + \|z\|_2^2\). Expressing in terms of the SVD we see that the middle term is given by \(\langle z, V_k\Sigma_k^{-1}U_k^*f\rangle\). Since \(z\) lies in the null-space of \(K\) we \(V_k^*z = 0\) so \(\|v\|_2^2= \|u\|_2^2 + \|z\|_2^2 \geq \|u\|_2^2\). We conclude that \(\|u\|_2^2\) is indeed the solution with the smallest norm.
We can combine the results of the former to to show that in this case \(u = K^\dagger f\) is a solution to the normal equations and that it is the one with the smallest norm.
2.4.3. Tikhonov regularization¶
Show that the solution to the variational problem
is given in terms of the SVD of \(K \in \mathbb{R}^{m\times n}\) as
where \(k = \text{rank}(K)\).
Answer
First, write down the corresponding normal equations \(K^*Ku + \alpha u = K^*f\), so \(u = (K^*K + \alpha I)^{-1}K^*f\). Use the full SVD of \(K = U\Sigma V^*\) with \(U\in\mathbb{R}^{m\times m}\), \(V\in\mathbb{R}^{n\times n}\) and \(\Sigma \in \mathbb{R}^{m\times n}\) whose first \(k\) diagonal entries contain the singular values. We find \(u = (V^*\Sigma^*\Sigma V + \alpha I)^{-1}V\Sigma^*U^*\). Use that \(V^*V = VV^* = I\) and \(\Sigma_n^2 = \Sigma^*\Sigma\) an \(n \times n\) matrix with \(k\) non-zero diagonal elements. Then the normal equations become \(u = V(\Sigma_n^2 + \alpha I)^{-1}\Sigma^*U^*f\). We realise that \(\Sigma^*U^*f\) will only contain contributions from the \(k\) non-zero singular values: \(\Sigma^*U^*f = (\sigma_1 u_1^*f,\sigma_2 u_2^*f, \ldots, \sigma_k \langle u_k, f\rangle, 0, 0, \ldots, 0 )\). Thus, we get the desired result.
2.4.4. Gravity surveying¶
We can estimate the density distribution in the subsurface by measuring the local gravitational pull. The density profile \(u(x)\) is related to such measurements by a linear operator
Upon discretization with stepsize \(h = 1/n\), the inverse problem can be cast as a system of \(n\) equations in \(n\) unknowns \(Ku = f\).
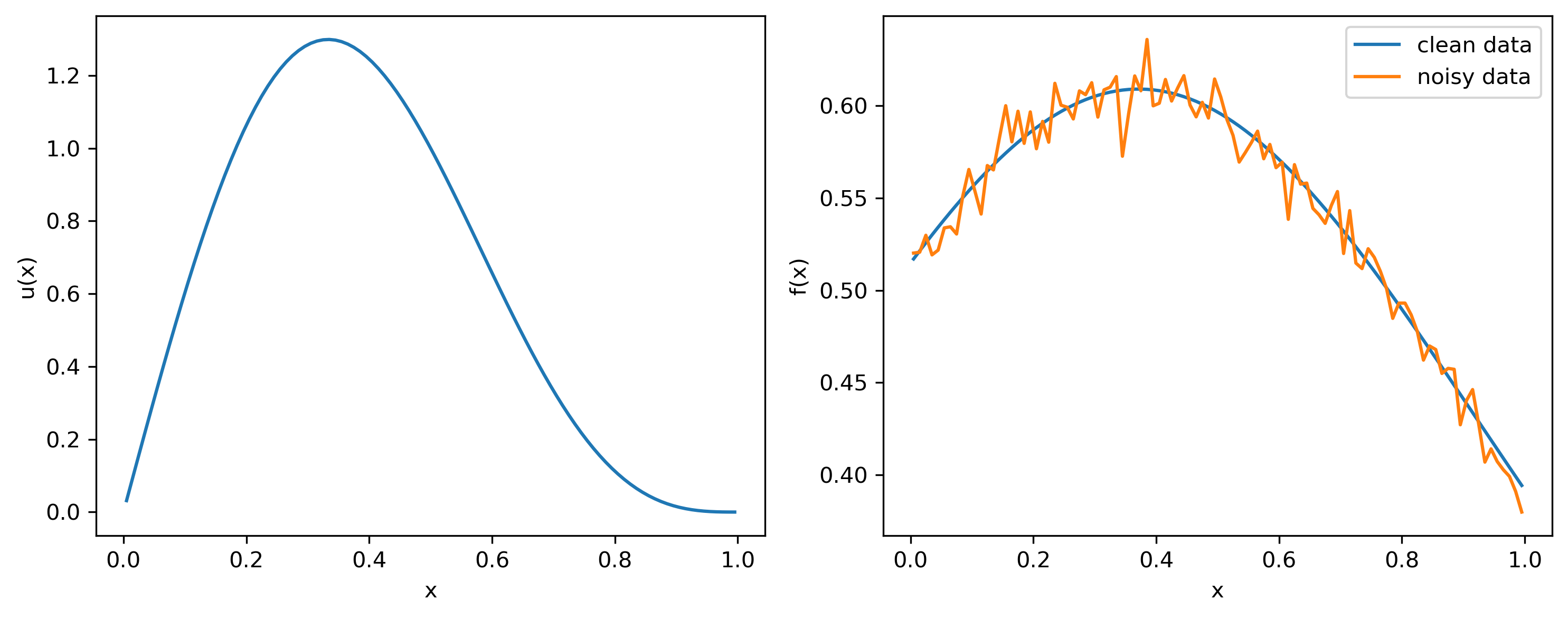
You can use the code provided below to generate the matrix and noisy data for a given \(u(x)\)
Plot the coefficients \(\langle u_i, f\rangle\) and the singular values \(\sigma_i\) to check the discrete Picard condition. What do you notice ?
Solve the inverse problem for noisy data using the (regularized) pseudo-inverse; compute the optimal \(\alpha\) by computing the bias and variance components of the error. Is this a practically feasible way to compute the optimal \(\alpha\)?
Compare the solutions for \(\alpha < \alpha_{\text{opt}}\), \(\alpha_{\text{opt}}\) and \(\alpha > \alpha_{\text{opt}}\) to the ground truth. What do you notice?
def getK(n):
h = 1/n;
x = np.linspace(h/2,1-h/2,n)
xx,yy = np.meshgrid(x,x)
K = h/(1 + (xx - yy)**2)**(3/2)
return K,x
import numpy as np
import matplotlib.pyplot as plt
import matplotlib as mpl
mpl.rcParams['figure.dpi'] = 300
# define forward operator
n = 100
delta = 1e-2
K,x = getK(n)
# define ground truth and compute data
u = np.sin(np.pi*x) + 0.5*np.sin(2*np.pi*x)
f = K@u
# add noise
noise = np.random.randn(n)
f_delta = f + delta*noise
# plot ground truth and data
fig, axs = plt.subplots(1,2)
axs[0].plot(x,u)
axs[0].set_xlabel('x')
axs[0].set_ylabel('u(x)')
axs[1].plot(x,f,label='clean data')
axs[1].plot(x,f_delta,label='noisy data')
axs[1].set_xlabel('x')
axs[1].set_ylabel('f(x)')
axs[1].legend()
fig.set_figwidth(10)
fig.tight_layout()
plt.show()
import numpy as np
import matplotlib.pyplot as plt
import matplotlib as mpl
mpl.rcParams['figure.dpi'] = 300
# define forward operator
def getK(n):
h = 1/n;
x = np.linspace(h/2,1-h/2,n)
xx,yy = np.meshgrid(x,x)
K = h/(1 + (xx - yy)**2)**(3/2)
return K,x
# parameters
n = 100
sigma = 1e-2
K,x = getK(n)
# define ground truth and compute data
u = np.sin(np.pi*x) + 0.5*np.sin(2*np.pi*x)
f = K@u
# add noise
np.random.seed(2)
noise = np.random.randn(n)
f_delta = f + sigma*noise
# SVD
U, s, Vh = np.linalg.svd(K, full_matrices=True)
# regularised pseudo inverse using Tikhonov
R_alpha = lambda alpha : Vh.T@np.diag(s/(s**2 + alpha))@U.T
# error, bias and variance for Tikhonov
na = 20
alpha = np.linspace(1e-6,2e-5,na)
error = np.zeros(na)
bias = np.zeros(na)
variance = np.zeros(na)
for k in range(na):
error[k] = np.linalg.norm(u - R_alpha(alpha[k])@f_delta)
bias[k] = np.linalg.norm(u - R_alpha(alpha[k])@f)
variance[k] = np.linalg.norm(R_alpha(alpha[k])@(f-f_delta))
# plot
fig,ax = plt.subplots(1,3)
ax[0].semilogy(s,'*',label=r'$\sigma_i$')
ax[0].semilogy(np.abs(U.T@f),'o',label=r'$|\langle u_i, f\rangle|$')
ax[0].semilogy(np.abs(U.T@f_delta),'o',label=r'$|\langle u_i, f^\delta\rangle|$')
ax[0].set_xlabel(r'$i$')
ax[0].set_xlabel(r'magnitude')
ax[0].set_ylim([1e-16,2])
ax[0].set_xlim([0,n])
ax[0].set_aspect('auto')
ax[0].legend()
ax[1].plot(alpha,error,label='total error')
ax[1].plot(alpha,bias,label='bias')
ax[1].plot(alpha,variance,label='variance')
ax[1].set_xlabel(r'$\alpha \cdot 10^{5}$')
ax[1].set_ylabel(r'error')
ax[1].set_xticks([5e-6,1e-5,1.5e-5,2e-5])
ax[1].set_xticklabels(['.5','1.0','1.5','2.0'])
ax[1].set_aspect('auto')
ax[1].legend()
ax[2].plot(x,u,label='ground truth')
ax[2].plot(x,R_alpha(1e-6)@f_delta,label=r'$\alpha = 10^{-6}$')
ax[2].plot(x,R_alpha(1.5e-5)@f_delta,label=r'$\alpha = 1.5\cdot 10^{-5}$')
ax[2].plot(x,R_alpha(1e-4)@f_delta,label=r'$\alpha = 10^{-4}$')
ax[2].set_ylim([-2,2])
ax[2].set_xlabel(r'$x$')
ax[2].set_ylabel(r'$u(x)$')
ax[2].set_aspect('auto')
ax[2].legend()
fig.set_figwidth(10)
fig.tight_layout()
Answer
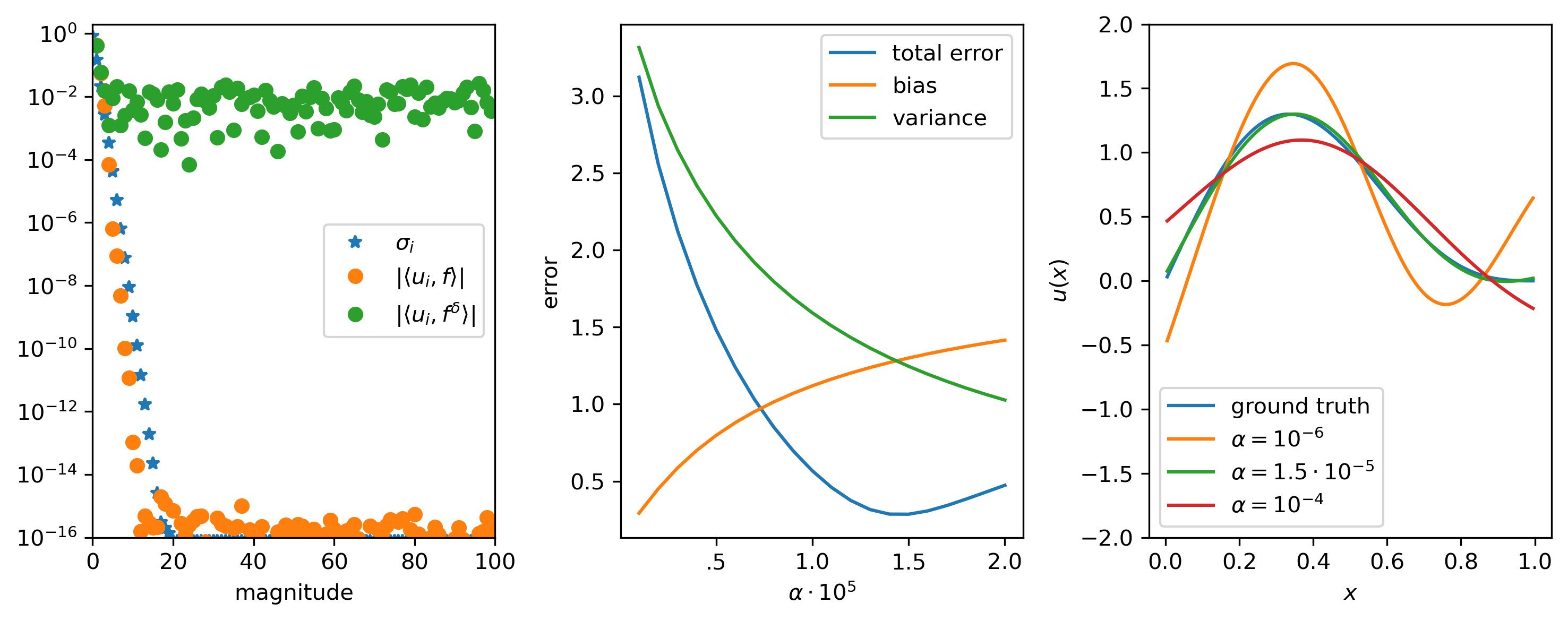
In the first figure we see that the Fourier coefficients of the noisy data definitely do not obey the discrete Picard condition. The Fourier coefficients of \(f\) may even be problematic as they are on the same level as the singular values for \(k > 20\). This has to do with the numerical rank of \(K\), which is roughly 20.
In the second figure we see the bias and variance parts of the error, the optimal \(\alpha\) (where they are equal) is approximately \(1.5\cdot 10^{-5}\). We cannot compute the optimal \(\alpha\) in this way in practice since we do not have access to the ground truth nor the noise-free data needed to compute the terms. You may also want to vary the random seed to explore the influence of the particular random instance of the noise. This further indicates how difficult it would be to choose an optimal value for \(\alpha\) based only on knowledge of the statistics of the noise.
Comparing the solutions we note that for smaller \(\alpha\) we get more oscillations in the solutions while for larger \(\alpha\) we get smoother solutions. Remarkably we get a really good reconstruction for \(\alpha = 1.5\cdot 10^{-5}\). This does not always have to be the case as you can explore in the assignment below.
2.5. Assignments¶
2.5.1. Convolution¶
We are going to solve a deconvolution problem \(Ku = f\), where \(K\) is a Toeplitz matrix with elements
and we are given noisy measurements
where the entries of \(e\) are normally distributed with mean zero and variance \(\delta^2\).
The goal of this assignment is to solve this inverse problem using a (truncated) SVD for two scenario’s
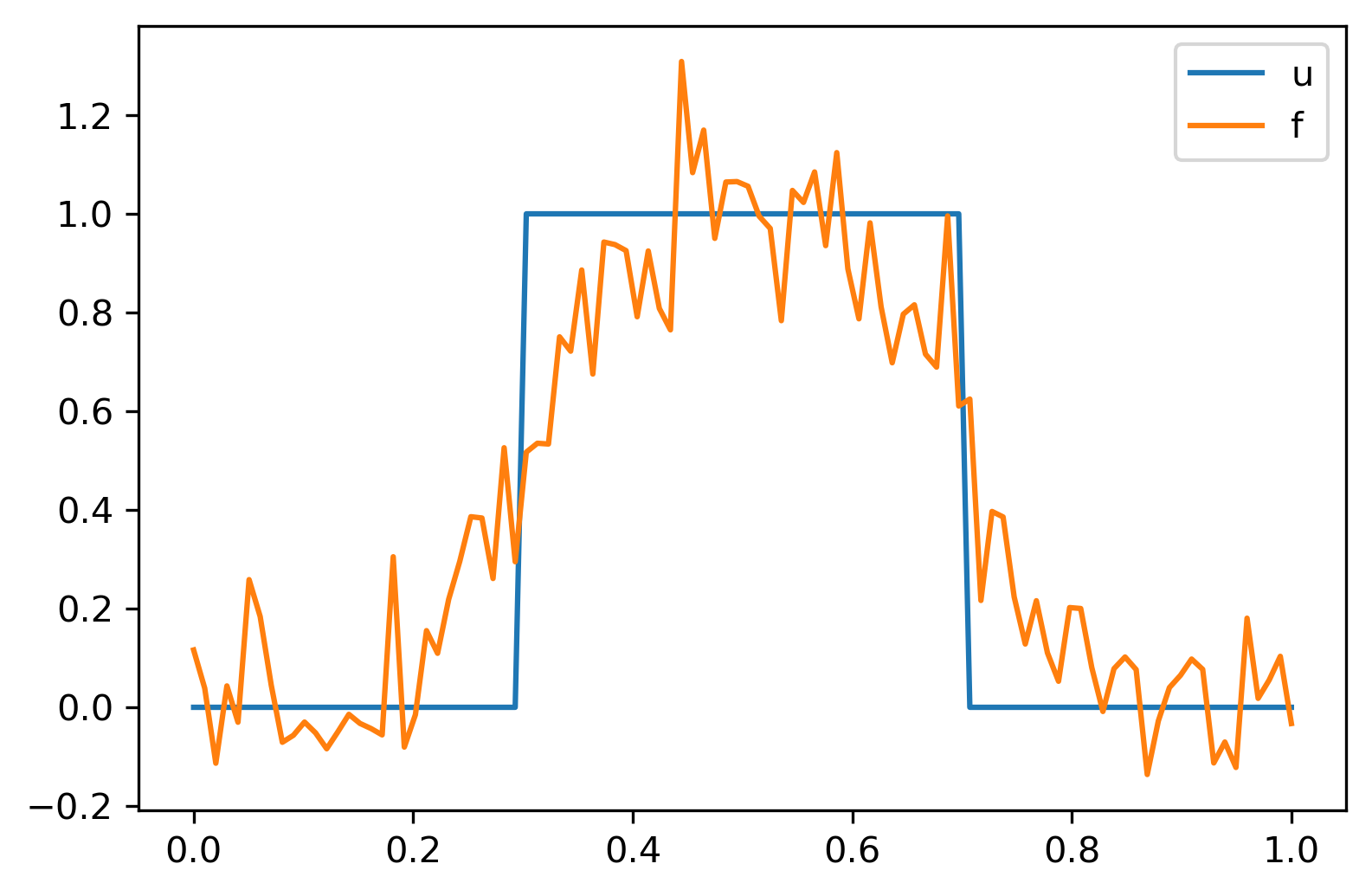
\(u(x) = H(x - 0.3) - H(x - 0.7)\),
\(u(x) = x(1-x)\),
where \(H\) denotes the Heaviside step function.
For each of the two scenarios answer the following questions:
Is this problem ill-posed? Give mathematical arguments in your reasoning and think carefully about the role of numerical parameters \(n\), \(a\), and \(\delta\).
Compute the (pseudo-)inverse of the matrix \(K\) using the SVD (for \(n=100\), \(a=100\)) and compute the backward error \(\|u - u^{\delta}\|_2\) for noise levels \(\delta = 0.001, 0.01, 0.1\) for both scenario’s using the code below. What do you observe?
Compute a regularized solution using a truncated SVD for noise levels \(\delta = 0.001, 0.01, 0.1\) for both scenario’s. Manually choose the truncation parameter \(k\) in each case to get the best possible solution. What do you observe?
Explain your observations by investigating what the singular vectors look like (think about the discrete Picard condition as well).
import numpy as np
import scipy.linalg as la
import matplotlib.pyplot as plt
import matplotlib as mpl
mpl.rcParams['figure.dpi'] = 300
# parameters and grid
n = 100
a = 100
delta = 1e-1
x = np.linspace(0,1,n)
# define forward operator
c = np.exp(-a*x**2)/((n-1)*np.sqrt(np.pi/a))
K = la.toeplitz(c)
# ground truth and data
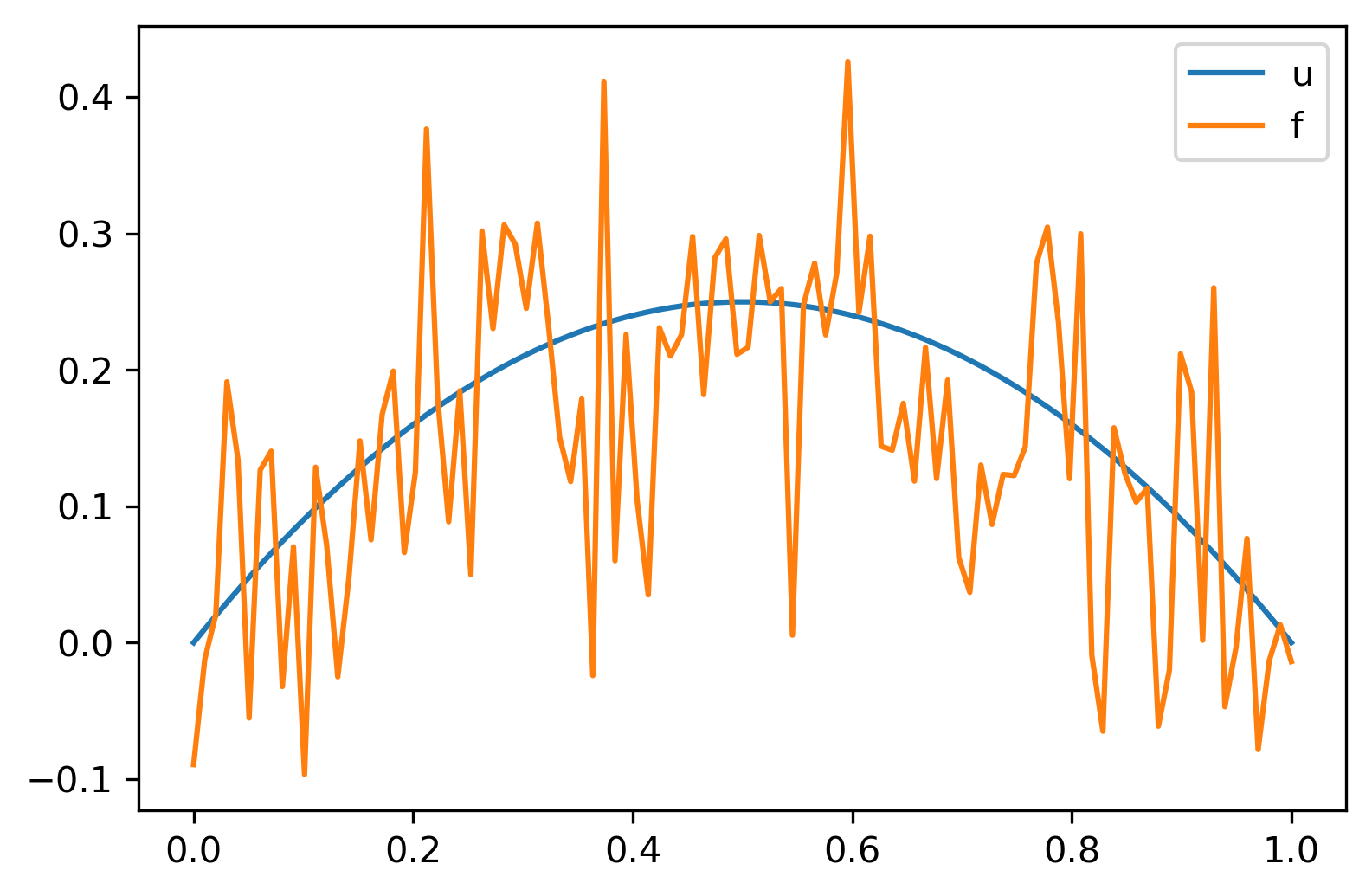
u = abs(x - 0.5)<.2
f = K@u + delta*np.random.randn(n)
# plot
plt.plot(x,u,label='u')
plt.plot(x,f,label='f')
plt.legend()
plt.show()
# parameters and grid
n = 100
a = 100
delta = 1e-1
x = np.linspace(0,1,n)
# define forward operator
c = np.exp(-a*x**2)/((n-1)*np.sqrt(np.pi/a))
K = la.toeplitz(c)
# ground truth and data
u = x*(1-x)
f = K@u + delta*np.random.randn(n)
# plot
plt.plot(x,u,label='u')
plt.plot(x,f,label='f')
plt.legend()
plt.show()